
ChatGPTみたいな自分専用のAIエージェントを作ろうとすると、いちばん最初にぶつかるのが「会話履歴やユーザーの記憶をどこに保存するか」問題。
「データベース使えばいいんでしょ?」 — はい、そうです。でもどう使うかで結構世界が変わります。
今回は Turso という新しめのデータベースサービスを触ってみたら、AIエージェントに向いてる設計がたくさんあって面白かったので、データベース初心者にもわかるように整理します。
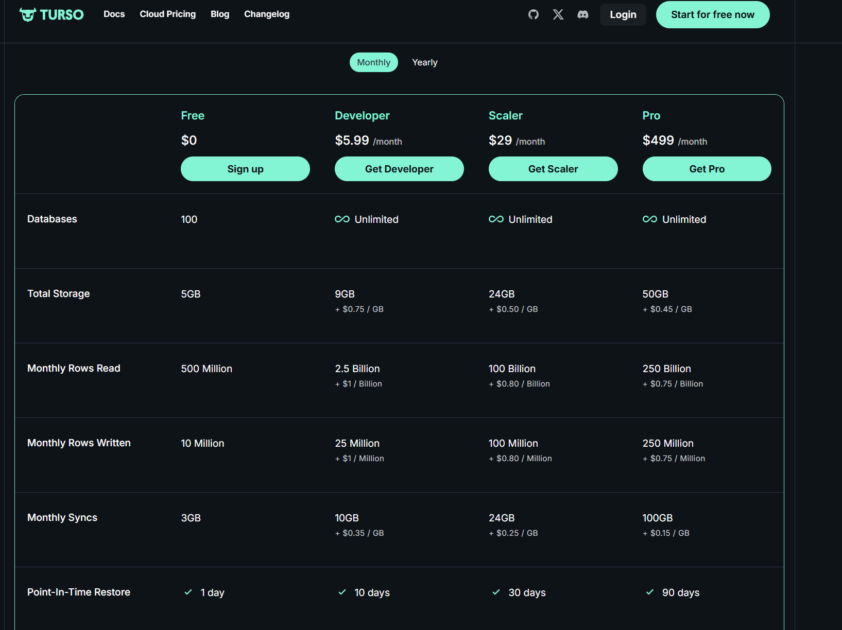
Turso は無料枠が結構あって、DBは100個まで・合計5GBまで無料で作れます。これがほんと破格。(2026/5/7)
「普通のデータベース」だと何が困るのか
普通、AIエージェントの会話履歴を保存しようと思ったら、こんな構造を考えますよね:
CREATE TABLE conversations (
id INTEGER,
user_id INTEGER, -- ← 誰の会話か
role TEXT,
content TEXT,
created_at TIMESTAMP
);そして取り出すときは:
SELECT * FROM conversations WHERE user_id = 123;これ、動きはします。が、AIエージェント用途だと地味に困るポイントがあります。
| 困りごと | 何が起きるか |
|---|---|
| WHERE句を1行書き忘れたら全員の会話が漏れる | バグが即・個人情報漏洩 |
| 「私のデータ全部消して」が地味に大変 | DELETE FROM … WHERE … を全テーブル分書く必要あり(GDPR対応の地獄) |
| スケールするとテーブルが超巨大に | 数百万人分の会話が1つのテーブルに混ざる |
| 個人別にバックアップ、が面倒 | dump → grep user_id みたいな涙ぐましい作業 |
要するに、「論理的には分離されてるけど物理的には1つ」という状態が問題なんですね。
Tursoが出してきた答え:「なら、ユーザーごとに別DBにしちゃえばいい」
ここで Turso の発想がおもしろい。
ユーザーごとに データベースそのもの を分けてしまえ
え、それ普通できないでしょ?って思うじゃないですか。PostgreSQLでDB1個作るのって、それなりに重い(時間もコストもかかる)作業ですからね。
でも Turso のベース技術 libSQL(SQLiteの分散クラウド版) は、DB作成が異常に軽い。
- 作成にかかる時間: 1〜2秒
- 作成にかかる費用: ほぼ無料(使わないDBはストレージ料金のみ)
- 作成方法: HTTP API 1リクエスト
つまり「ユーザーが新規登録したらDB作成」がプログラム的にできる。これが他のDBにはない決定的な違いです。
Tursoの魅力 — まず押さえる3つ
詳しい理屈は後にして、まずこの3つだけ覚えればTursoの強みは伝わります。
① ユーザーごとに「完全独立DB」が爆速で作れる
1ユーザー=1DB(または1エージェント=1DB)が簡単に作れて、即時破棄も可能。データ隔離が圧倒的に簡単で安全。
② エッジ配置で世界中どこでも超低遅延
30以上のリージョンにレプリカを自動配置。読み取りがミリ秒台で爆速。グローバルアプリやモバイルとの相性が抜群。
③ AI時代に最適なネイティブVector Search
拡張不要でベクトル検索がサクサク。RAGや長期記憶を、軽量・低コストで実装できる。
この3つが揃っているDBサービスは、いまのところ他に見当たりません。
実際に作ってみた
ということで、「Authすら使わずに、ブラウザが発行する匿名ID(UUID)だけで、1人1DBの個人AIエージェント」 を作ってみました。
完成したアプリ画面:
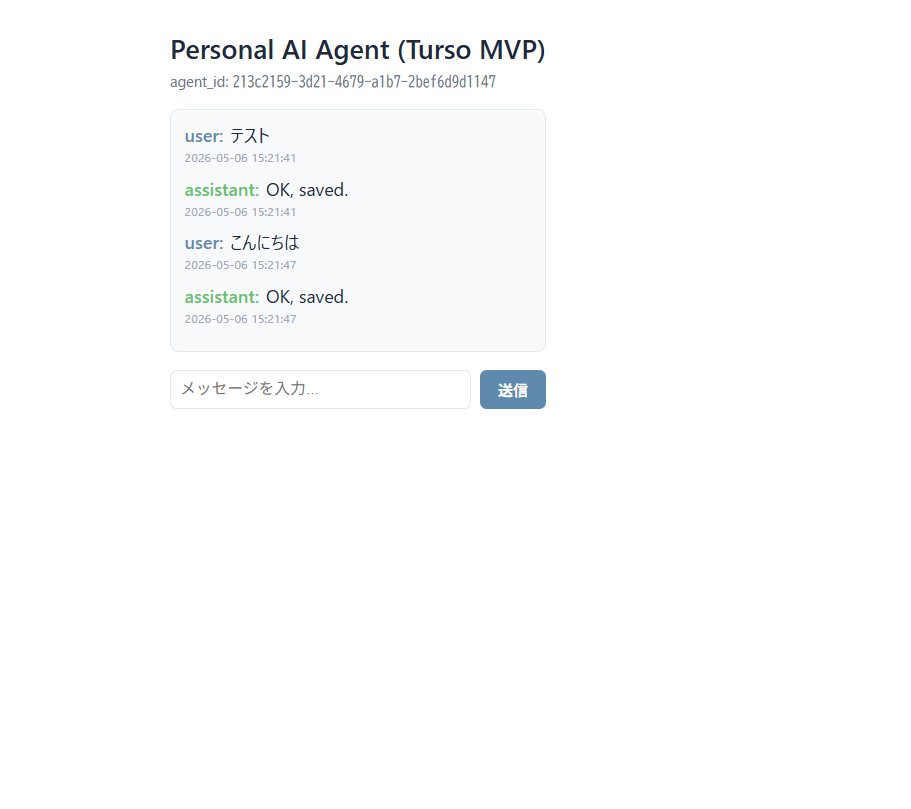
ブラウザを別ウィンドウ(シークレットモード)で開くと…
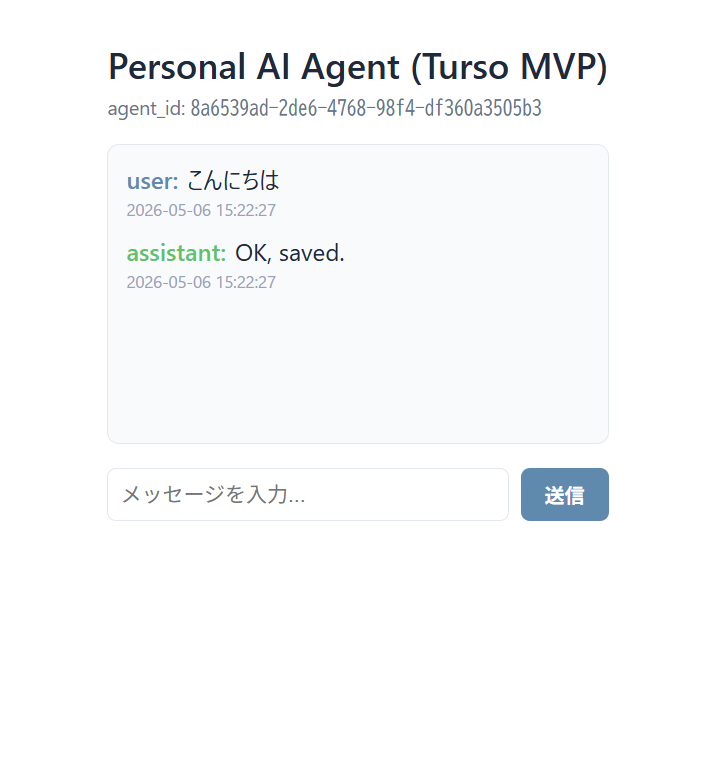
完全に別の会話になっています。当たり前?いや、ここがポイント。
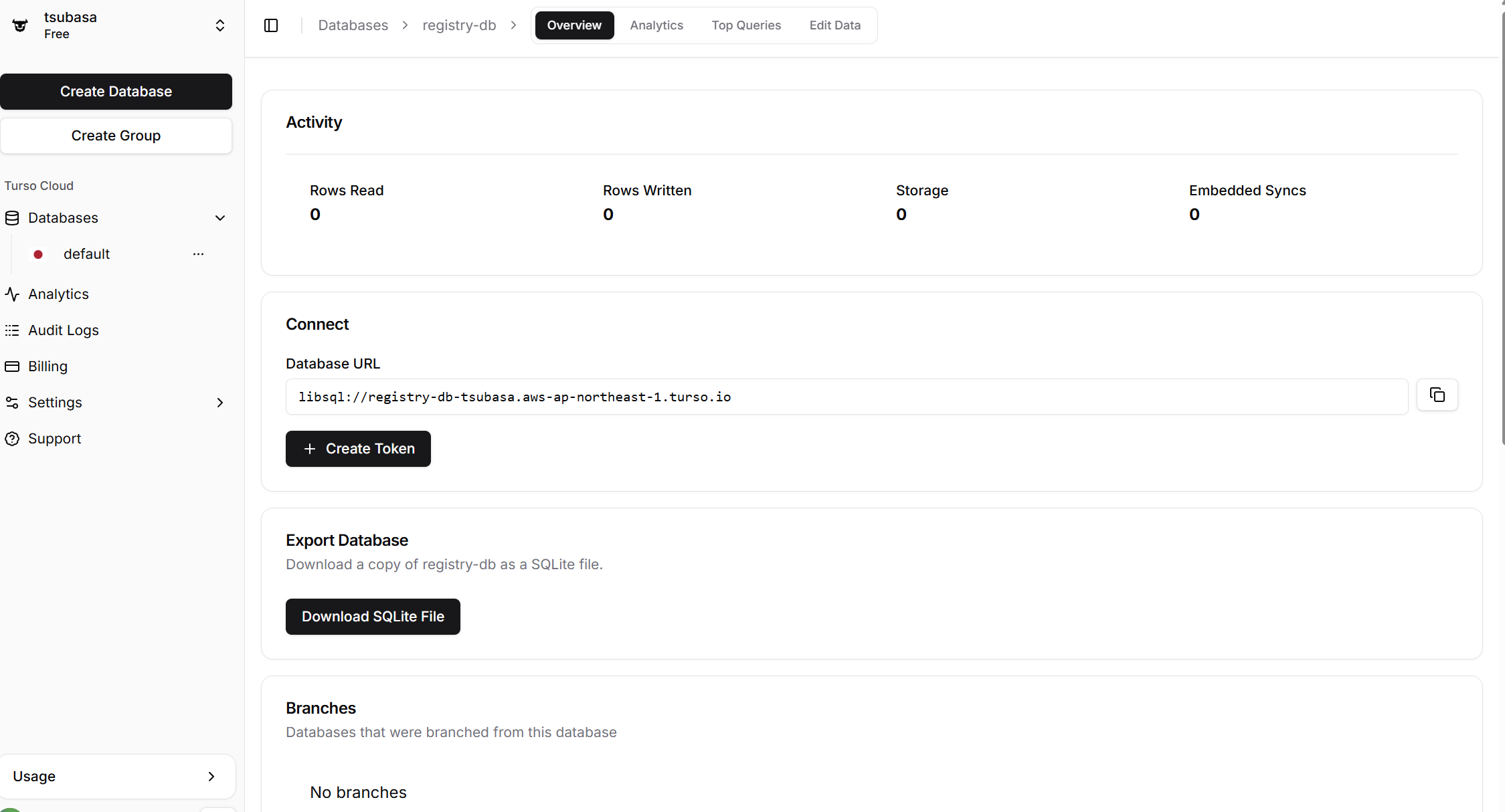
Tursoのダッシュボードを見ると:
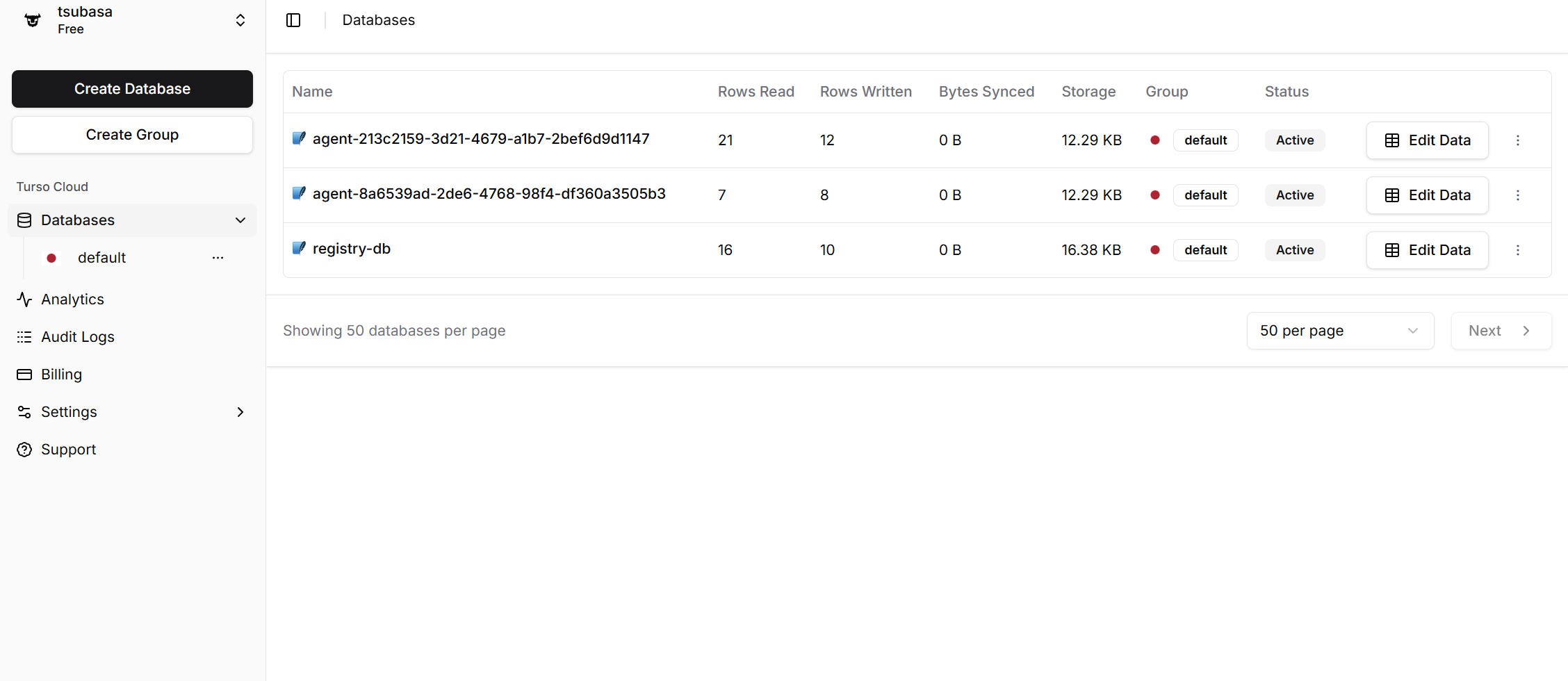
registry-db(管理用・1つ)agent-213c2159-...(ブラウザ1専用)agent-8a6539ad-...(ブラウザ2専用)
物理的に分離された3つのデータベースが並んでいます。それぞれの中身を見ると:
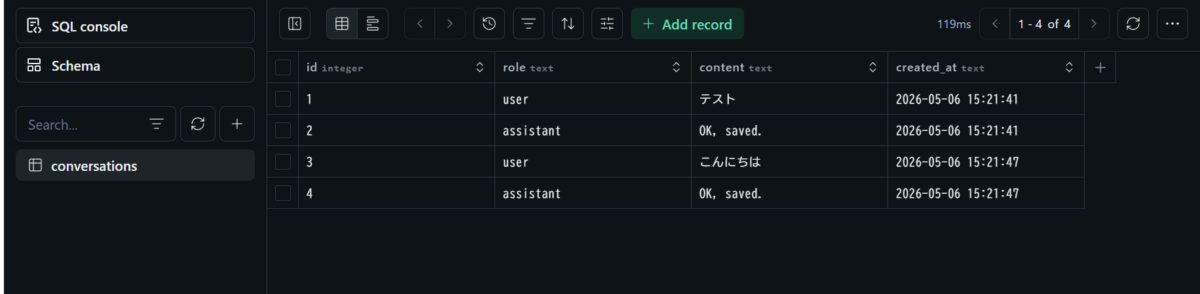
ブラウザ2のメッセージしか入っていません。物理的に分離されているので、WHERE句を書き忘れるリスクがそもそも存在しないのです。
なぜこれがAIエージェントに向いているのか — 5つの理由
1. データ漏洩リスクがゼロ
物理的に別のDBなので、SQLにバグがあっても他人のデータは絶対に見えない。「絶対」というのは普通プログラミングで使えない言葉ですが、ここでは使えます。
2. ユーザー削除がコマンド1発
「私のデータを全部消してください」と言われたら:
turso db destroy agent-{user_uuid}これだけ。GDPR完全対応です。テーブル横断で DELETE 文を書く必要なし。
3. 一時的な「使い捨てDB」も作れる
Tursoにはエフェメラル(揮発性)DBという機能があって、「終わったら消える一時的なDB」を作れます。匿名チャットや、機密性の高い相談に最適。
4. Vector Searchが標準で入っている
AIエージェントには「過去の会話から関連するものを探す」機能(RAG = Retrieval-Augmented Generation)が必須なんですが、TursoはVector Searchが組み込み。別途Pineconeとか契約しなくていい。
5. HTTPで動くからサーバレスとの相性が抜群
普通のDBは「常時接続」を前提とするけど、libSQLはHTTP APIで叩けます。Vercel・Cloudflare Workers・AWS Lambdaみたいなサーバレス環境でも普通に使える。
データベース初心者が押さえるべきTurso用語
| 用語 | ざっくり言うと |
|---|---|
| libSQL | SQLiteの”クラウド対応・分散対応”版 |
| Turso | libSQLをマネージドで提供するサービス(Supabaseの”DB特化版”みたいな立ち位置) |
| Platform API | DBを作る・消す・トークン発行する用のHTTP API |
| Database Token | 特定のDBに接続するためのJWT(パスワードみたいなもの) |
| Group | DBの配置(リージョン)を決めるグルーピング |
逆に SQLite を触ったことがあるなら、ほとんど同じ感覚で使えます。SQLは普通のSQL。
開発時間: 数十分
このアプリ、コードは合計300行くらい。Authなし・LLMなし・会話保存だけの最小MVPですが:
- 起動:
npm run dev - 接続: 環境変数5つ(Tursoの管理画面でコピペするだけ)
- 動作確認: ブラウザでメッセージ送信 → DBに記録される
これだけです。
次のステップ
このMVPに段階的に肉付けすると、本格的なAIエージェントになります:
- LLM結線: 固定文 “OK, saved.” の代わりに Groq / OpenAI / Claude API を呼ぶ
- 長期記憶: 重要な会話を
memoriesテーブルに分離して embedding 化 - Vector Search: 過去の関連記憶をプロンプトに注入する RAG
- ドキュメント取り込み: PDF/テキストをアップロードして横断検索
これらすべて、Tursoの中だけで完結します。
まとめ
「1ユーザー = 1データベース」という、普通のDBではコスト的に成立しないアーキテクチャが、Tursoだと現実的に動く。
これが、TursoがAIエージェント向きな最大の理由です。
データベース初心者の方は、「テーブル設計でなんとかする」という常識から一歩外れて、「DBそのものを設計のパーツにする」という発想を覚えると、設計の自由度がぐっと広がりますよ。

