

「最近よく聞くDeepSeek・Qwen・Gemma などの話題のオープン系AIモデルを試してみたい。でもGPU買うのは高いし、環境構築も難しそう…」
「ChatGPT以外のAI、特にDeepSeekやQwenみたいなモデルを触ってみたいけど、何から始めればいいかわからない」
「自分のPC内だけでAIを動かしたい」という用途であれば、当ブログでも紹介した Ollama という選択肢があります(参考:インターネット無しでも動くAI「Ollama」とは?メリット・デメリットを解説)。ただし Ollama は自分のPCのCPU・メモリ・GPUを直接使うので、スペックに自信がない方や、DeepSeek-V4-pro のような数百Bパラメータ級の最大モデルを試したい方には少しハードルがあります。
そこでもう一つの選択肢としておすすめなのが、GPUの王者 NVIDIA が運営する 「build.nvidia.com」(以下 NVIDIA Build)です。NVIDIAのクラウドGPU上で動いている DeepSeek・Qwen・Gemma などの最新オープンウェイトモデルを、ブラウザから無料で試せます。自分のPCスペックは一切関係なく、クレジットカード登録もPythonの環境構築も最初は不要。AIに初めて触れる方でも、この記事の手順通りに進めれば10分で動かせます。
⚠️ 重要な前提:本記事は build.nvidia.com を「開発・評価・プロトタイピング用途で個人が試す」ことを前提に解説しています。
無料 Endpoint は NVIDIA の利用規約上 “evaluation and development” 目的が前提であり、本番サービスへの組み込み・商用運用には別途 NVIDIA Enterprise / NIM 契約、Self-hosted NIM、または AWS / GCP / Azure 経由の利用が必要です。レート制限・SLA も保証されず、モデルのラインナップも予告なく変更されます。個人情報・社外秘・顧客データは絶対にプロンプトに入れないでください。
「自前GPU」「Ollama」の壁と、NVIDIA Build が解決するもの
DeepSeek・Qwen・Gemma などのオープンウェイトモデルを「自分の手元で動かしたい」と考えると、選択肢は大きく2つあります。
- 自前GPUにフルセットアップ:高性能GPU(30万〜数百万円)+CUDA・Python・Docker など専門知識が必要
- Ollama などのローカルAIツール:インストール自体は簡単だが、結局は自分のPCのスペック(特にメモリ・GPU)に依存。一般的なノートPCだと小型モデルしか動かせず、最大級モデルはほぼ不可能
共通の課題は「動かしてみないとモデルの良し悪しが分からないのに、試すコストが高い」こと。NVIDIA Build はこの課題をズバッと解決してくれます。NVIDIAのデータセンターに最新モデルが既に立ち上がっているので、ユーザーはAPIを叩くだけで使える。自分のPCスペックは一切関係ありません。本格的にローカル運用を考える前の、検証・比較・体験用ツールとして最高の環境です。
事前に準備するもの(10分で揃います)
- パソコン(Windows / Mac / Linux 何でもOK)
- ブラウザ(Chrome や Edge)
- メールアドレス(Googleアカウント等で簡単サインアップ可能)
- (Step 6 のみ)Python 3.10 以上 ※ ブラウザで試すだけならPython不要
クレジットカードは登録不要です。「ちょっと試したいだけなのに支払い情報を求められて萎える」あの体験はありません。
Step 1:build.nvidia.com にアクセス&ログイン
まずは build.nvidia.com にアクセスし、画面右上の「Login」ボタンを押します。Googleアカウント等で30秒で登録完了します。
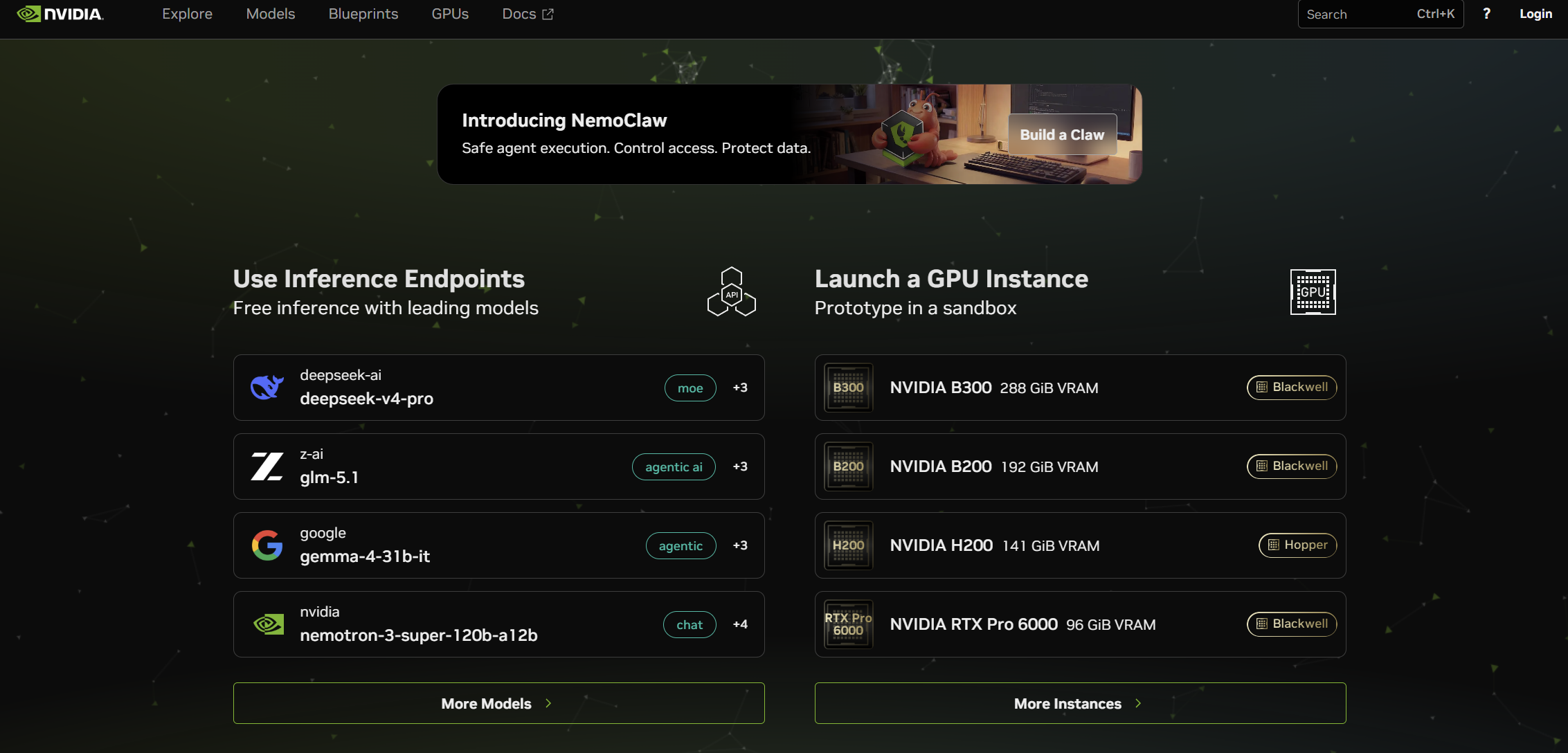
ログインするとトップに「Use Inference Endpoints」と「Launch a GPU Instance」の2つの入口が並んでいます。
- Use Inference Endpoints=NVIDIAが用意してくれた “無料お試し窓口”。今回はこちらを使います。
- Launch a GPU Instance=自分専用のGPUを借りて自由にモデルを動かす(有料)
「Endpoint(エンドポイント)」という単語は “AIに話しかけるための窓口” くらいに思っておけば大丈夫です。
Step 2:「Free Endpoint」のモデルだけに絞り込む
上部メニューの「Models」をクリックすると、モデル一覧が表示されます。左サイドバーの「Filters」で「Free Endpoint」にチェックを入れると、無料で叩けるモデルだけに絞り込めます。
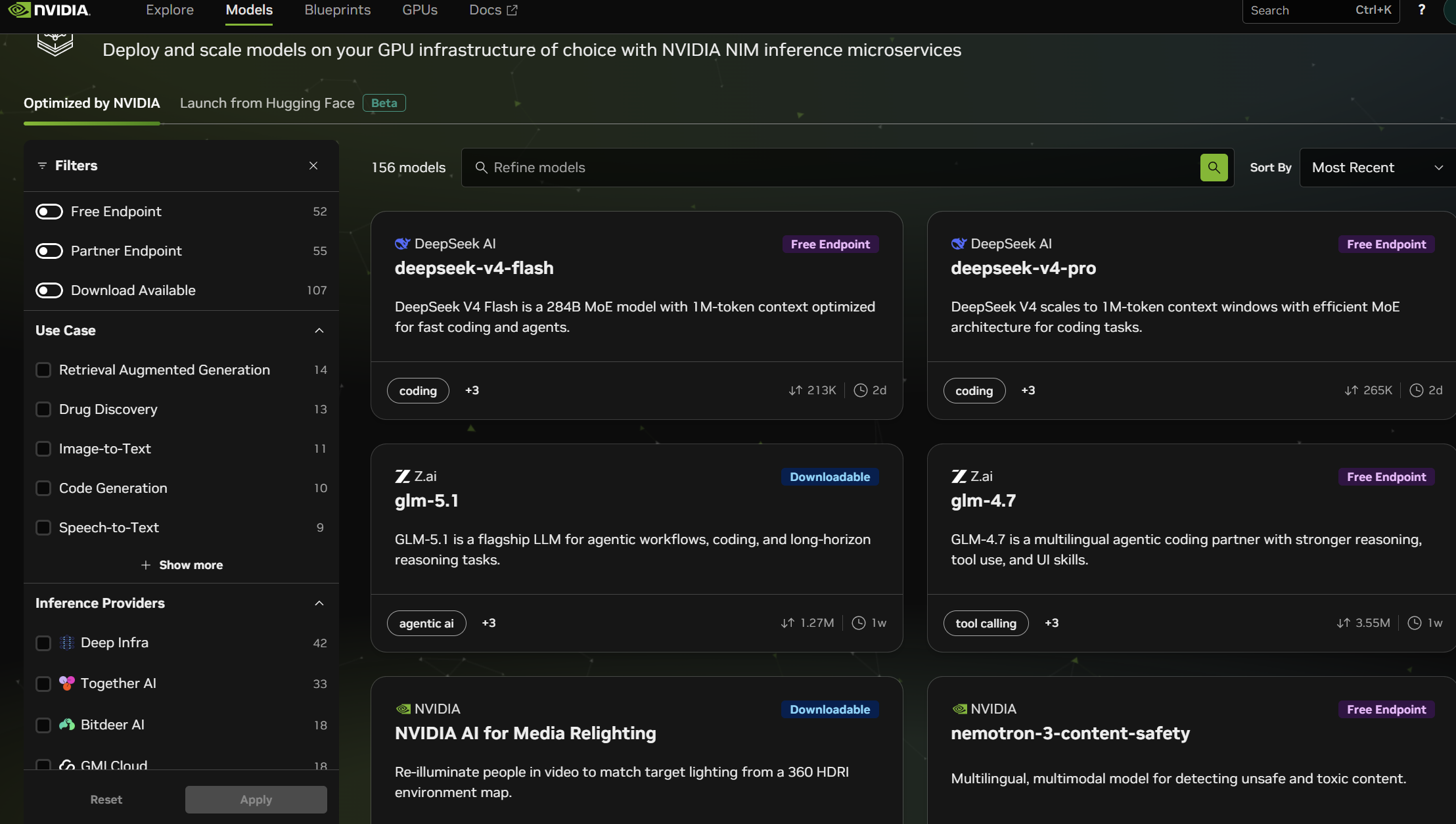
2026年4月時点で無料で試せる代表的なモデルは以下の通り。SNSやニュースで話題になったあのモデルが、すぐ目の前にあります。
- DeepSeek-V4-pro / V4-flash:中国DeepSeek社の推論・コード生成に強いモデル
- Qwen3-coder-480b:Alibaba製。コーディング特化で256kトークンの長文も得意
- Google Gemma-4-31b-it:軽量で扱いやすい汎用モデル
- NVIDIA Nemotron シリーズ:NVIDIA独自の最適化モデル
- Z.ai GLM-5.1 / GLM-4.7:エージェント用途で評価の高いモデル
Step 3:「Publisher(提供元)」や「Use Case(用途)」で絞り込む
サイドバーの「Publisher」フィルタで提供元の会社を選べます。NVIDIA、Google、Meta、Mistral AI、DeepSeek、Qwen、Moonshot AI などが並びます。
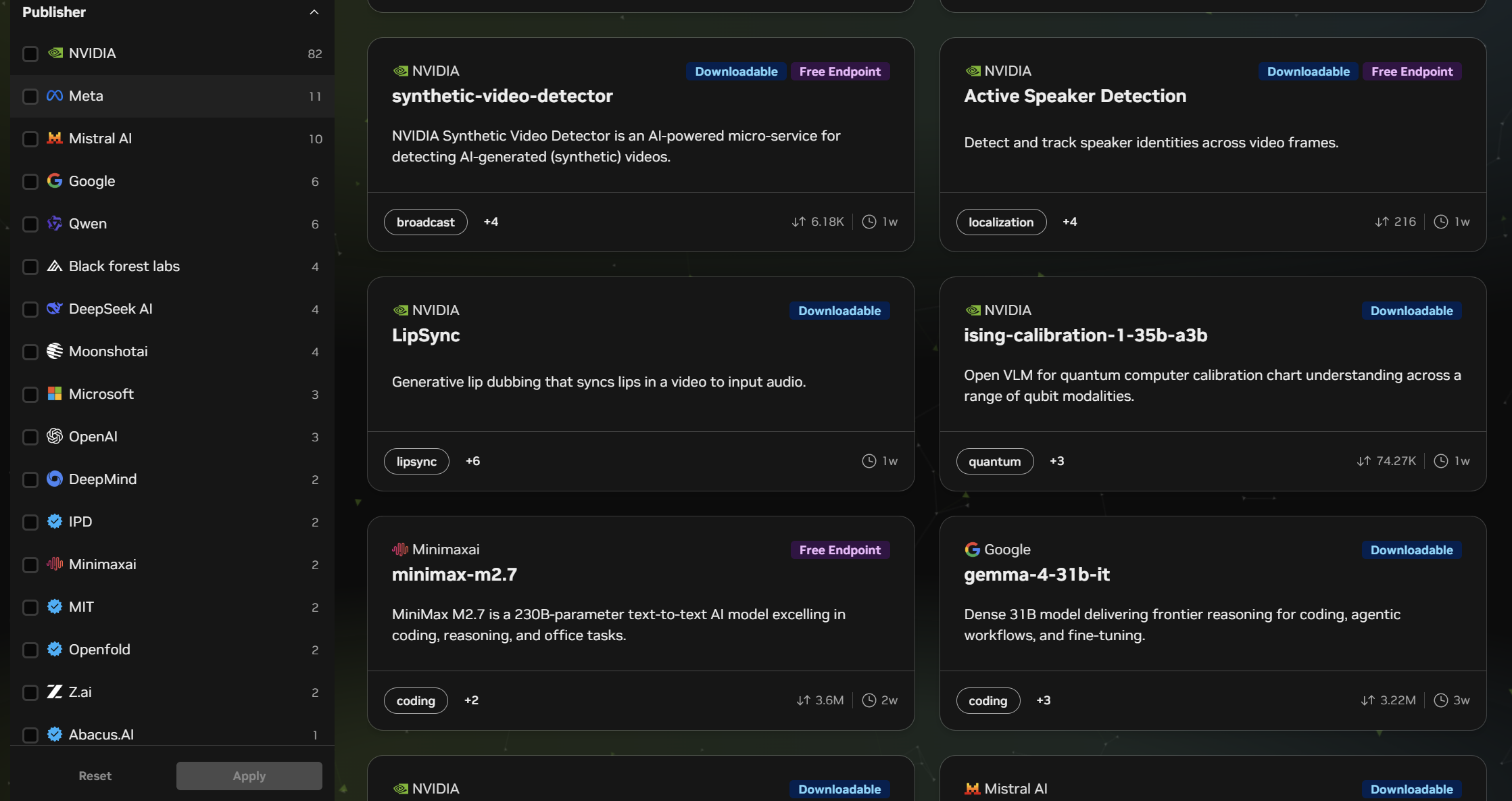
「Use Case」フィルタからは目的別に絞り込めます。
- Code Generation:プログラミング支援
- Image-to-Text:画像を読み取って説明させる
- Speech-to-Text:音声を文字起こし
- Retrieval Augmented Generation:社内文書検索AI(いわゆるRAG)
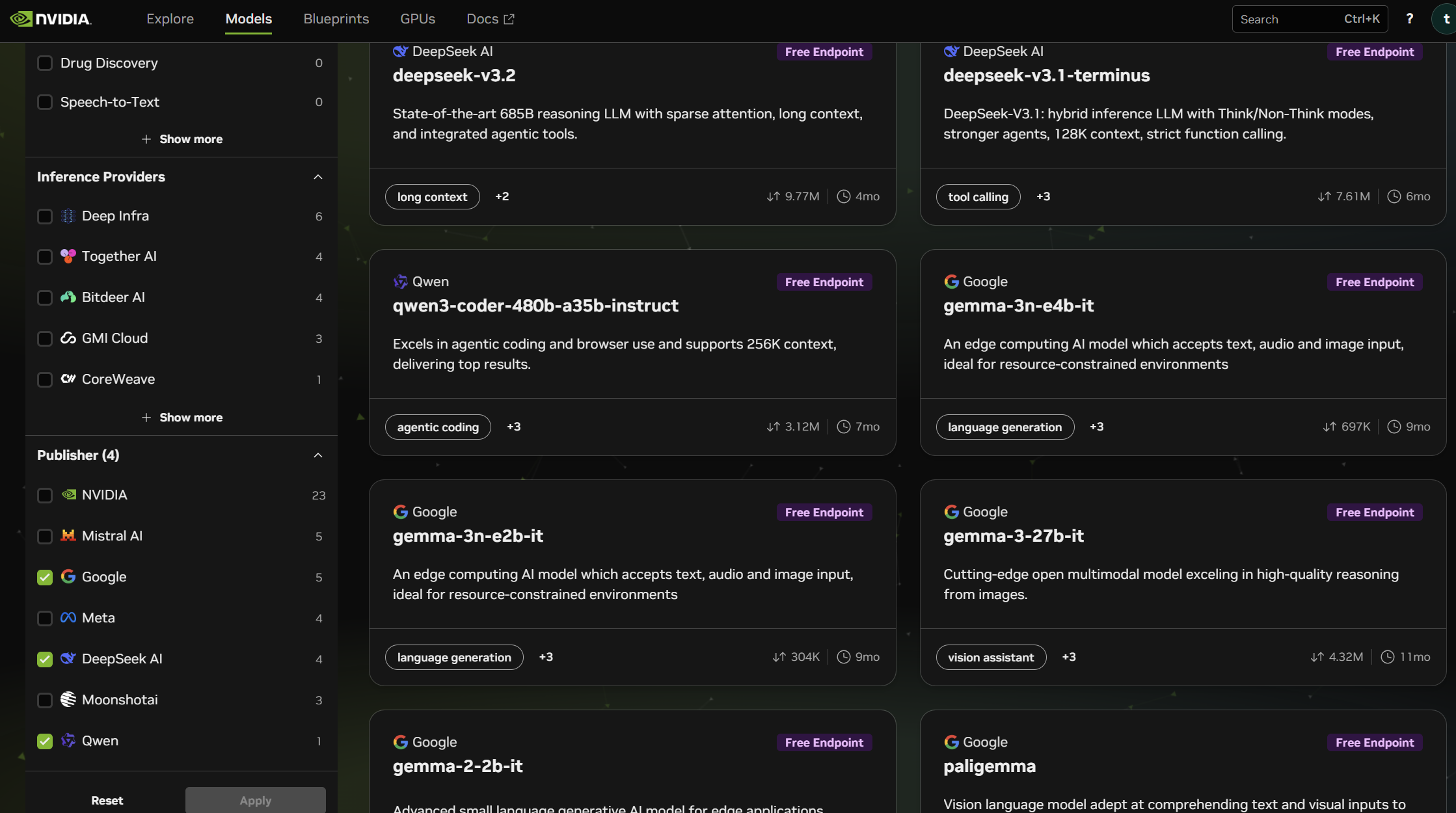
Step 4:ブラウザでそのまま試してみる
気になるモデルをクリックすると、その場で試せるチャット画面が開きます。下部の入力欄に質問を打ち込んで送信するだけで、すぐに回答が返ってきます。Pythonを書く必要はまだありません。
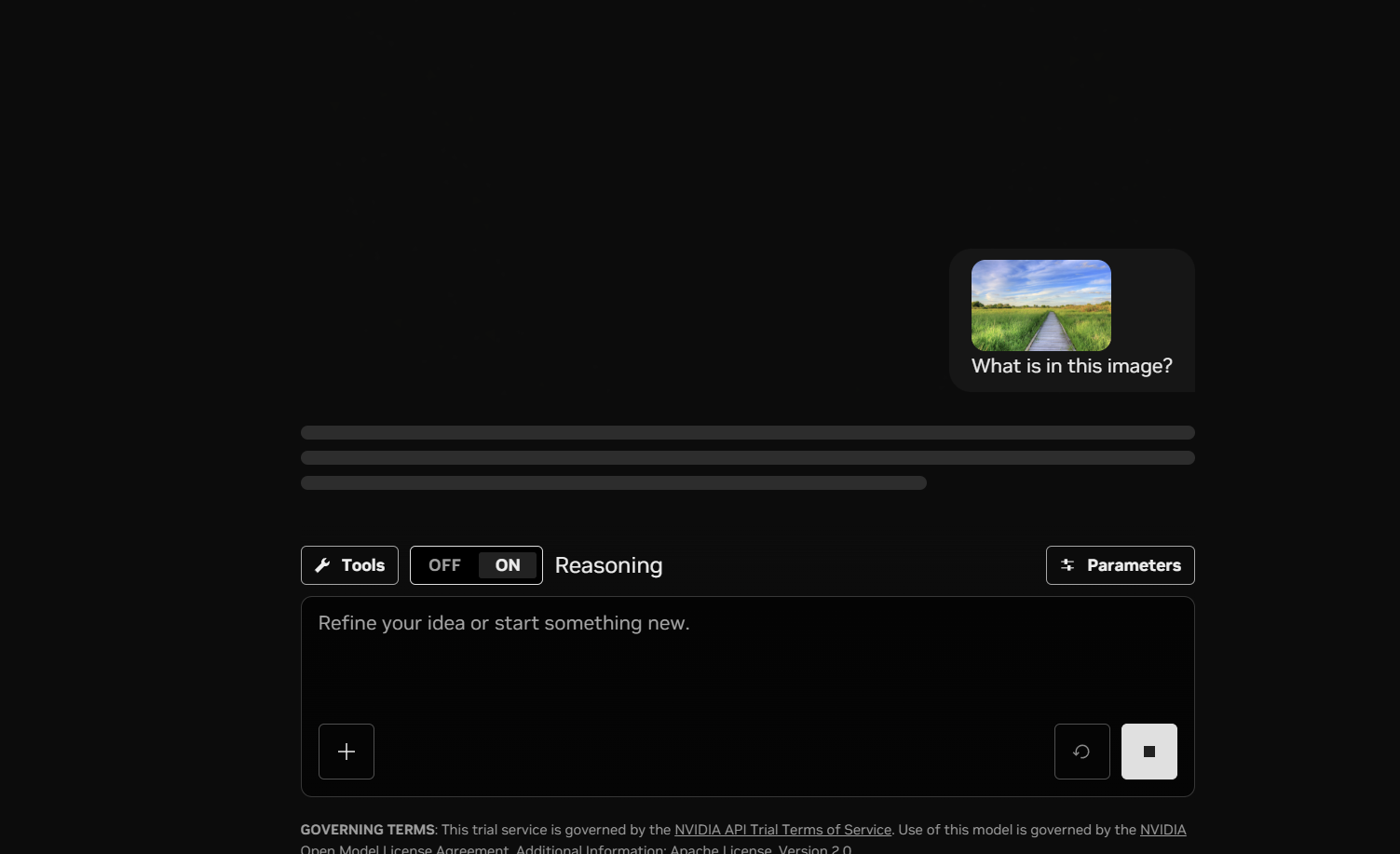
画像対応モデルなら、画像をドラッグ&ドロップして「What is in this image?(この画像には何が写ってる?)」のように画像認識も試せます。「Reasoning(思考過程の表示)」や「Tools(外部ツール連携)」のON/OFFも下部スイッチで切り替えられます。
ここで気に入ったモデルが見つかったら、いよいよ自分のコードから呼び出してみましょう。
Step 5:API Key(自分専用の合鍵)を発行する
「APIキー」は、ざっくり言うと “自分専用のAIアクセスパス” です。これがないとAIに話しかけることはできません。AIに話しかけるための「IDパスワードのようなもの」と思ってください。
画面右上のアカウントアイコン(自分のイニシャルが表示された丸いアイコン)から「API Keys」を開き、「Generate API Key」ボタンをクリックします。
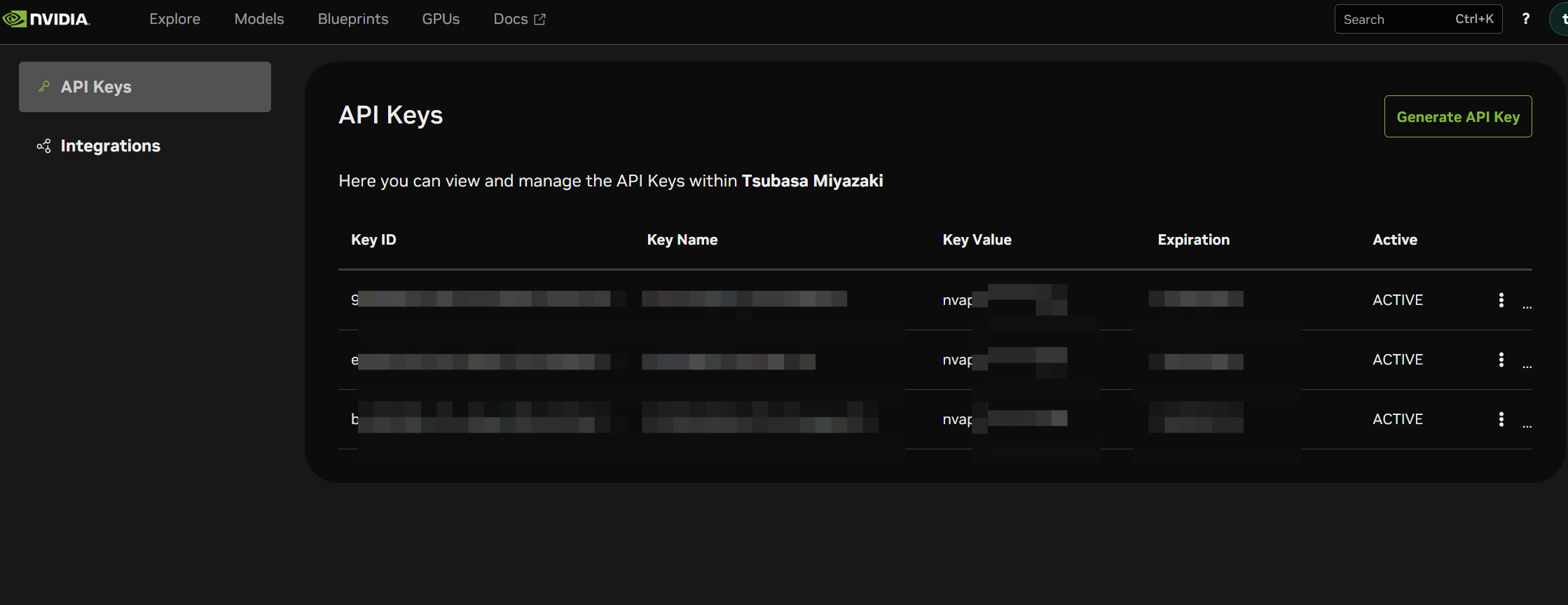
キー名(例:my-first-key)と有効期限を入れると、nvapi- で始まる文字列が発行されます。
⚠️ 超重要:このキーは発行直後の1回しか表示されません。必ずすぐコピーして、メモ帳など安全な場所に保管してください。漏らすと他人に使われてしまうので、GitHubに公開するコードには絶対に直書きしないこと。後述の通り、環境変数に入れるのが鉄則です。
Step 6:コードから呼び出す(実は超ラク)
裏ワザ:「View Code」ボタンを使う
実は build.nvidia.com の各モデルページには 「Get API Key(コード取得)」ボタンが用意されていて、そのモデル用の Python・Node.js・curl のサンプルコードをそのままコピペできるようになっています。
初心者なら、まずはこのサンプルコードをそのままコピーして、APIキーを差し替えるだけでOKです。自分でゼロから書く必要はありません。
Python の準備(初めての方向け)
Pythonをまだ入れていない方は、公式サイトからインストールしてください(Mac はターミナルで brew install python でもOK)。
続いて、ターミナル(コマンドプロンプト)で以下を実行し、OpenAI互換ライブラリを入れます。
pip install openaiサンプルコード(DeepSeek を呼び出す例)
適当なフォルダに test_nvidia.py という名前でファイルを作り、以下を貼り付けます。
import os
from openai import OpenAI
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key=os.environ.get("NVIDIA_API_KEY"), # 環境変数から読む(推奨)
)
resp = client.chat.completions.create(
model="deepseek-ai/deepseek-v4-pro",
messages=[
{"role": "user", "content": "こんにちは。自己紹介してください。"}
],
)
print(resp.choices[0].message.content)
ターミナルで以下を実行して、APIキーを環境変数に設定します(nvapi-xxxxx の部分は自分のキーに置き換え)。
# Mac / Linux
export NVIDIA_API_KEY="nvapi-xxxxxxxxxxxxxxxxxxxx"
# Windows (PowerShell)
$env:NVIDIA_API_KEY="nvapi-xxxxxxxxxxxxxxxxxxxx"あとは Python ファイルを実行するだけ。
python test_nvidia.pyこれだけで、世界最先端のAIモデルが自分のコードから呼び出せます。model の文字列を変えるだけで別のモデルに切り替えられるので、「同じプロンプトを複数モデルに投げて精度を比較する」といった使い方も簡単です。
よくあるエラーと対処
- ModuleNotFoundError: No module named ‘openai’
→pip install openaiを実行していない。ターミナルでもう一度実行してください。 - 401 Unauthorized
→ APIキーが間違っているか、環境変数が読み込めていません。echo $NVIDIA_API_KEY(Mac/Linux)で値が表示されるか確認を。 - model not found
→ モデル名は build.nvidia.com の「View Code」ボタンに表示される正確な文字列をコピーしてください。 - Rate limit exceeded
→ 無料枠の上限に達しています。少し時間を置くか、別モデルを試してください。
これは厳密には「ローカルLLM」じゃない、けど…
正確に言うと、NVIDIA Build は NVIDIAのクラウドGPU上で動いているAIモデルにAPIで話しかけるサービスです。つまり「ローカル(自分のPC内)で動かしている」わけではありません。
ただし、ここで提供されているDeepSeek・Qwen・Gemmaなどのオープンウェイト系モデルは、本来ローカルLLMとして自分のGPUで動かすことができる種類のモデルです。だから NVIDIA Build を「ローカルLLMを買う前に試せる場」として使うのは、極めて理にかなった判断です。
- 「このモデルなら自社業務に使えそう」と分かったら、本番ではローカル/オンプレでも運用できる
- 逆に「微妙」と分かれば、GPU購入を見送れる(数十万〜数百万円の節約)
- 同じプロンプトを複数モデルに投げて、ベストなモデルを選定できる
“買う前に試す”が無料でできる。これが NVIDIA Build の本当の価値です。
“完全ローカル” の Ollama と比べてどっちがラク?
「ローカルLLMといえば Ollama を聞いたことがある」という方も多いと思います。Ollama は本当に自分のPCの中だけでAIを動かせる強力なツールです(Ollamaの詳細は当ブログの「インターネット無しでも動くAI『Ollama』とは?メリット・デメリットを解説」をご覧ください)。
NVIDIA Build と Ollama は似て非なるものなので、初心者の方が「どっちから試せばいい?」を判断できるよう、比較表を作りました。
| 項目 | NVIDIA Build | Ollama |
|---|---|---|
| 動作場所 | NVIDIAのクラウドGPU | 自分のPC(ローカル) |
| インターネット | 常時必要 | 初回ダウンロード後は不要 |
| インストール | 不要(ブラウザだけ) | 専用ソフトの導入が必要 |
| 必要なPCスペック | ほぼ無関係 | 高め(特にGPU推奨) |
| 試せるモデルの規模 | 数百Bパラメータの最大級モデルもOK | 数B〜数十B程度(PCスペック次第) |
| データプライバシー | クラウドに送信される | 完全に自分のPC内のみ |
| 料金 | 無料枠あり(共有) | 完全無料 |
| 立ち上げまでの時間 | 約3分(ログイン後すぐ) | 10〜30分(モデルDL含む) |
| 難易度 | ★☆☆(超かんたん) | ★★☆(インストールあり) |
結論:「目的別」に使い分けるのが正解
- とにかく最速で最新AIを触ってみたい人 → NVIDIA Build(10分で動かせる)
- 業務データ・機密情報を扱いたい人 → Ollama(完全オフライン、外部に出ない)
- 自分のPCに高性能GPUがある人 → Ollama(運用コストゼロ)
- PCスペックに自信がない人 → NVIDIA Build(自分のPC関係なし)
- 最大級のモデル(DeepSeek-V4-pro など)を触りたい人 → NVIDIA Build(個人PCでは無理)
- インターネットがない環境で使いたい人 → Ollama一択
つまり、“触り始めるラクさ”だけで言えば NVIDIA Build が圧勝。インストール不要・PCスペック不問・10分で動かせます。
一方、“プライバシーが命”な業務データを扱うなら Ollama 一択です。NVIDIA Build はあくまでクラウドにデータを送るので、社外秘の情報を投げてはいけません。
おすすめは 「両方使い分ける」。
① まず NVIDIA Build で「どのモデルが自分のニーズに合うか」を10分で見極める。
② 候補が決まったら、Ollama で同じモデルをローカルに落として、機密データでも安心して使う。
この流れなら、無駄なPC購入もなく、機密情報も守りながら、最適なAIモデルにたどり着けます。
⚠️ 無料枠を使うときの注意点(必読)
build.nvidia.com の無料 Endpoint は、あくまで「開発・評価・プロトタイピング用途」と明確に位置づけられています。以下の点に必ず留意してください。
- 本番サービスの基幹に組み込むのはNG。NVIDIAの利用規約上、無料 Endpoint は “evaluation and development” 目的が前提です
- 本番運用には別途契約が必要:NVIDIA Enterprise / NIM 契約、Self-hosted NIM(自社GPUへのデプロイ)、または AWS / GCP / Azure 経由の利用を選びます
- レート制限・SLA は保証されません。全ユーザー共有のキューで動いており、レイテンシも遅延もコントロール不能。エラー時の救済もありません
- モデルのラインナップは予告なく変わります。昨日まで無料だったモデルが翌週には有料化・終了することもあるため、本番依存は避けてください
- 個人情報・社外秘・顧客データは絶対にプロンプトに入れないこと。クラウドAPIなのでデータはNVIDIA側に送信されます。機密データを扱うなら Ollama などのローカル運用を選んでください
- AIの回答をそのまま外部公開しないこと(誤情報を出すこともあります)
まとめ
- 「ローカルLLMを試したい」が「GPUは高くて手が出ない」── そのギャップを埋めるのが NVIDIA Build
- クレジットカード不要、ブラウザだけで DeepSeek・Qwen・Gemma などを今すぐ試せる
- API Key を発行すれば、OpenAI互換APIとして自分のコードに数分で組み込める
- “買う前に試す”が無料でできるのが最大のメリット。本番ローカル運用の意思決定にも使える
「ChatGPT以外のAIも比較してみたい」「自社プロダクトにオープン系LLMを組み込めるか検証したい」── そんな方は、まず build.nvidia.com で複数モデルを叩き比べてみるのがおすすめです。1つのAPIキーで色々なモデルを試せるので、選定の手間がぐっと減ります。
AppTalentHub では、こうしたAI活用・DX推進の伴走支援を行っています。「自分の業務にAIを組み込みたい」「どのモデルが自社に合うか相談したい」というご要望はお気軽にお寄せください。

