

「フォルダ経営」を考えていると、似た発想が AI コーディングの世界でも出てきていることに気づきました。Claude Code 周辺で「skill graph」と呼ばれるスキル群です。これは何で、どんな時に使うものなのか。観察したことを書き残しておきます。
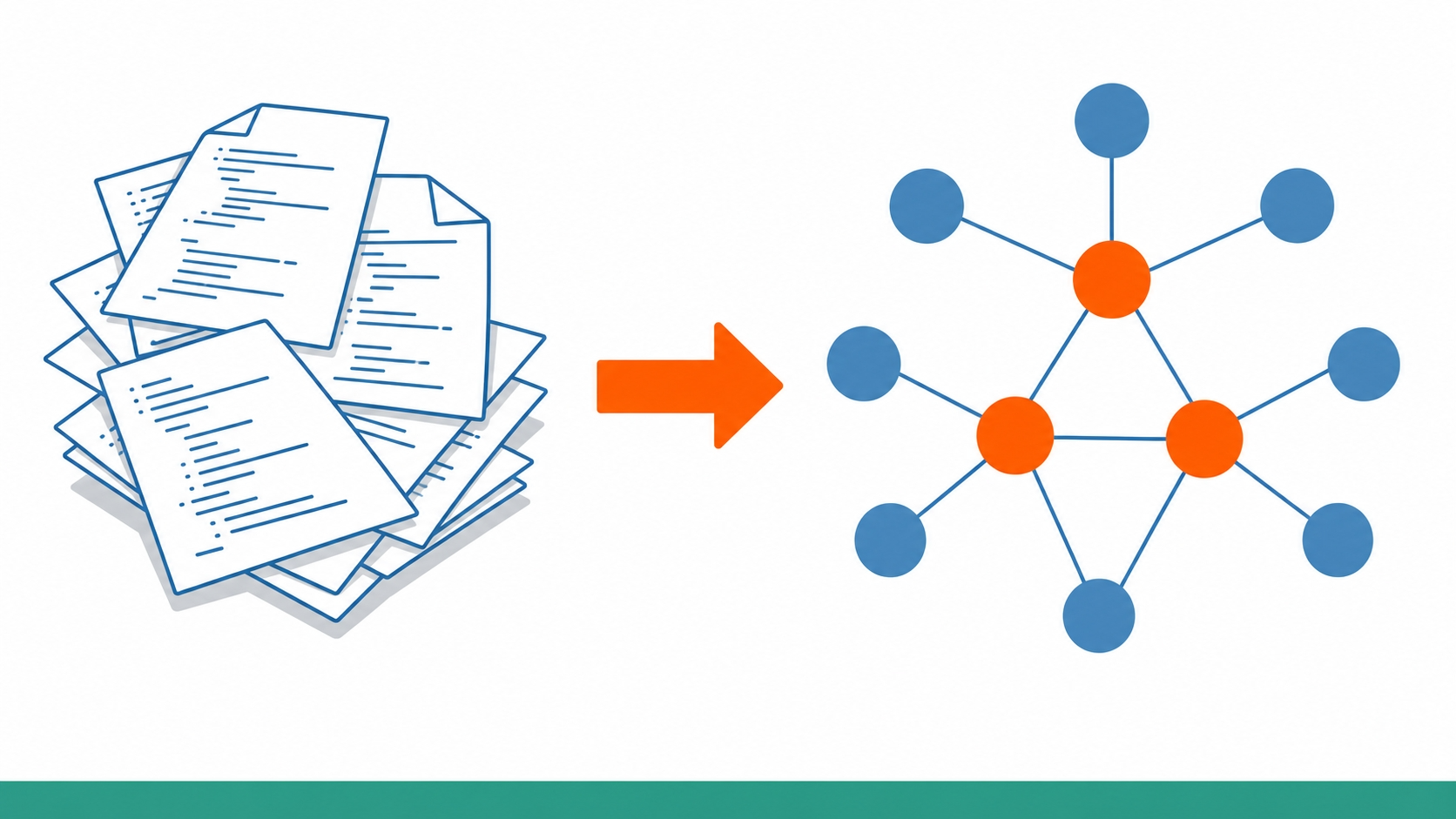
skill graph とは何か
最初に押さえておきたいのは、これが Claude Code の公式機能ではないということです。コミュニティが作っているサードパーティ製スキルの総称的な呼び方で、中身はおおむね「コードベースを知識グラフに変換しておく事前マップ系スキル」です。
リポジトリの関数・依存関係・呼び出し関係をあらかじめ解析しておき、知識グラフとして保存。AI エージェントがコードを読むときに、グラフを参照して必要な箇所だけピンポイントで取りに行く、という発想です。
なぜこういうものが出てきたか
大規模なリポジトリを AI に読ませると、毎回ファイルを走査します。同じファイルを何度も読み込み、同じ情報を会話のたびに繰り返し舐めることになる。規模が増えるほど線形にトークンとレイテンシが膨らみます。
これを事前に構造化キャッシュしておけば、必要な箇所だけ短く読める、というのが共通のコンセプトです。
実在しているスキル例
GitHub 上で実在を確認できたものをいくつか挙げておきます(2026年5月時点)。
Graphify
- リポジトリ: github.com/safishamsi/graphify
- 対応: Claude Code / Cursor / GitHub Copilot CLI / Gemini CLI / Codex / OpenCode / Aider など
- 仕組み: tree-sitter でコードを解析(コード本体はローカル処理)。ドキュメント・PDF・画像は LLM で意味抽出
- 特徴: god nodes(接続度の高い概念ノード)の検出、モジュール横断の意外な接続の検出、推奨質問の生成
SocratiCode
- リポジトリ: github.com/giancarloerra/SocratiCode
- エンタープライズ向けコードベース・インテリジェンス
- MCP 統合経由でセマンティック検索とポリシー検索のハイブリッド
GRACE Marketplace
- リポジトリ: github.com/osovv/grace-marketplace
- 正式名: Graph-RAG Anchored Code Engineering
- 契約駆動の AI コード生成プラットフォーム
- 知識グラフを基盤に Agent Skills を構築
関連: tree-sitter は tree-sitter 公式サイト を参照。
共通する仕組み
実装の細かい違いはあれど、構造はだいたいこんな順番です。
- パース層: tree-sitter や LSP などでコードの構文木を取得
- グラフ構築層: ノード(関数・クラス・モジュール)とエッジ(呼ぶ・継承・参照)を抽出
- 保存層: JSON や SQLite、グラフ DB、ベクトルストアの組み合わせ
- 検索層: 自然言語クエリをグラフ走査に変換、該当ノードだけ AI に渡す
- 更新層: コード変更を検知して差分再構築
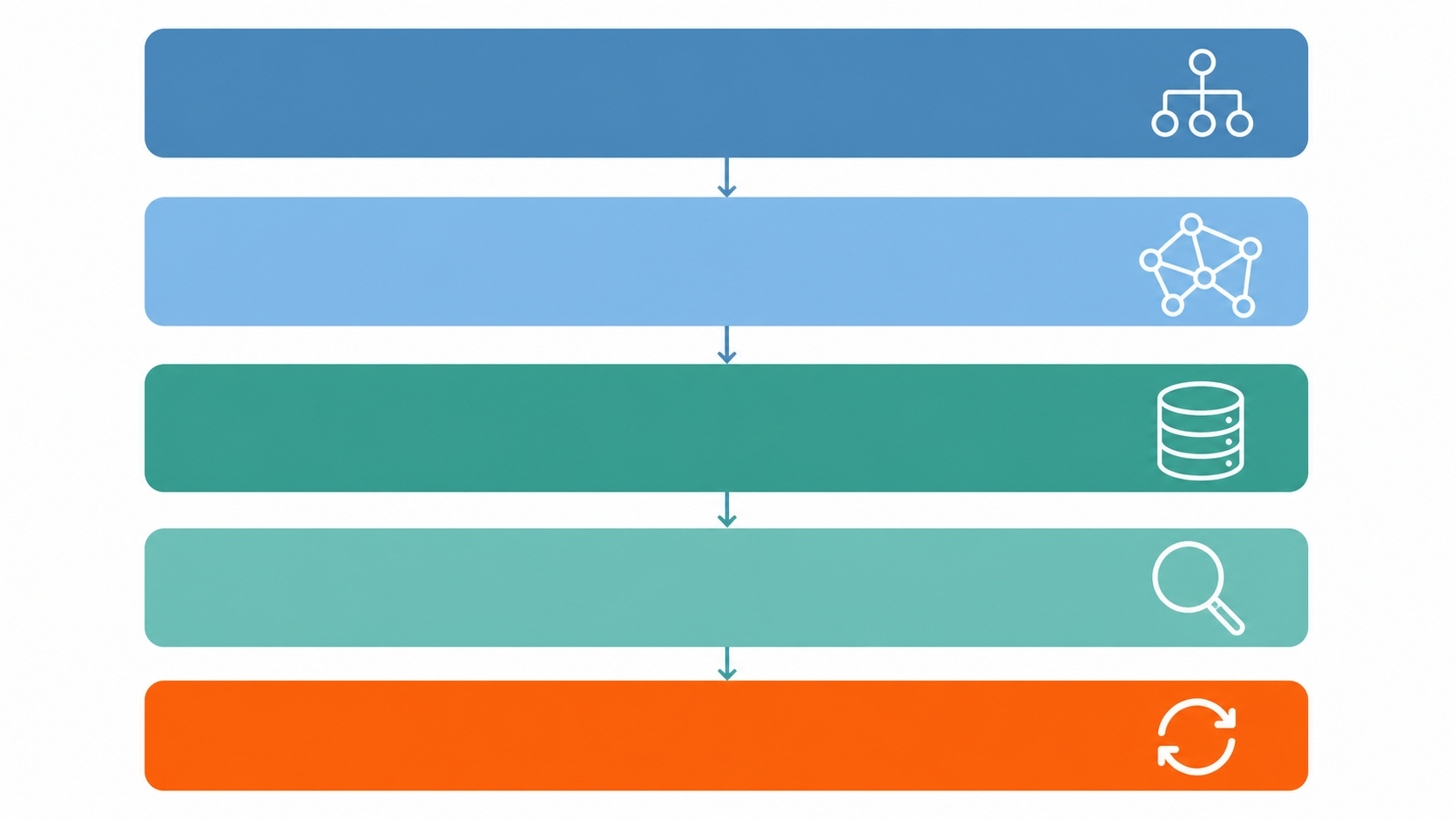
5番目の更新層が運用上の一番のポイントです。コードが日々変わる現場で、グラフをどう新鮮に保つか。ここで詰まると陳腐化したマップを AI が信じ込むので、足元の利便性が落ちます。
いつ効く、いつ効かない
入れて効くのは、おおむね次の3条件が揃ったときです。
- コードベースが大きい(目安: 5万行以上、ファイル200個以上)
- 寿命が長い(数ヶ月から数年メンテし続ける)
- AI エージェントが頻繁にそのコードを読む(毎日複数回、または自動エージェントが常時走る)
逆に、次のような状況では入れない方が良さそうです。
- プロトタイプや短期プロジェクト(グラフ作成コストが回収できない)
- アーキテクチャがまだ揺れている(グラフがすぐ陳腐化する)
- ファイル数が少ない(毎回読んでも安いし速い)
- 構造変更が週次レベルで起きている(メンテ負債になる)
フォルダ経営との接続
ここから本題です。skill graph の発想と「フォルダ経営」の発想は、設計思想が同系統だと感じます。
両者に共通するのは「事前に情報を構造化しておけば、後段の処理が劇的に楽になる」という考え方です。読める化が先にあって、その上での意思決定や応答が速くなる。
ただし対象が違います。
- フォルダ経営: 経営情報を「人」が読める形に整える
- skill graph: コードベースを「AI エージェント」が読める形に整える
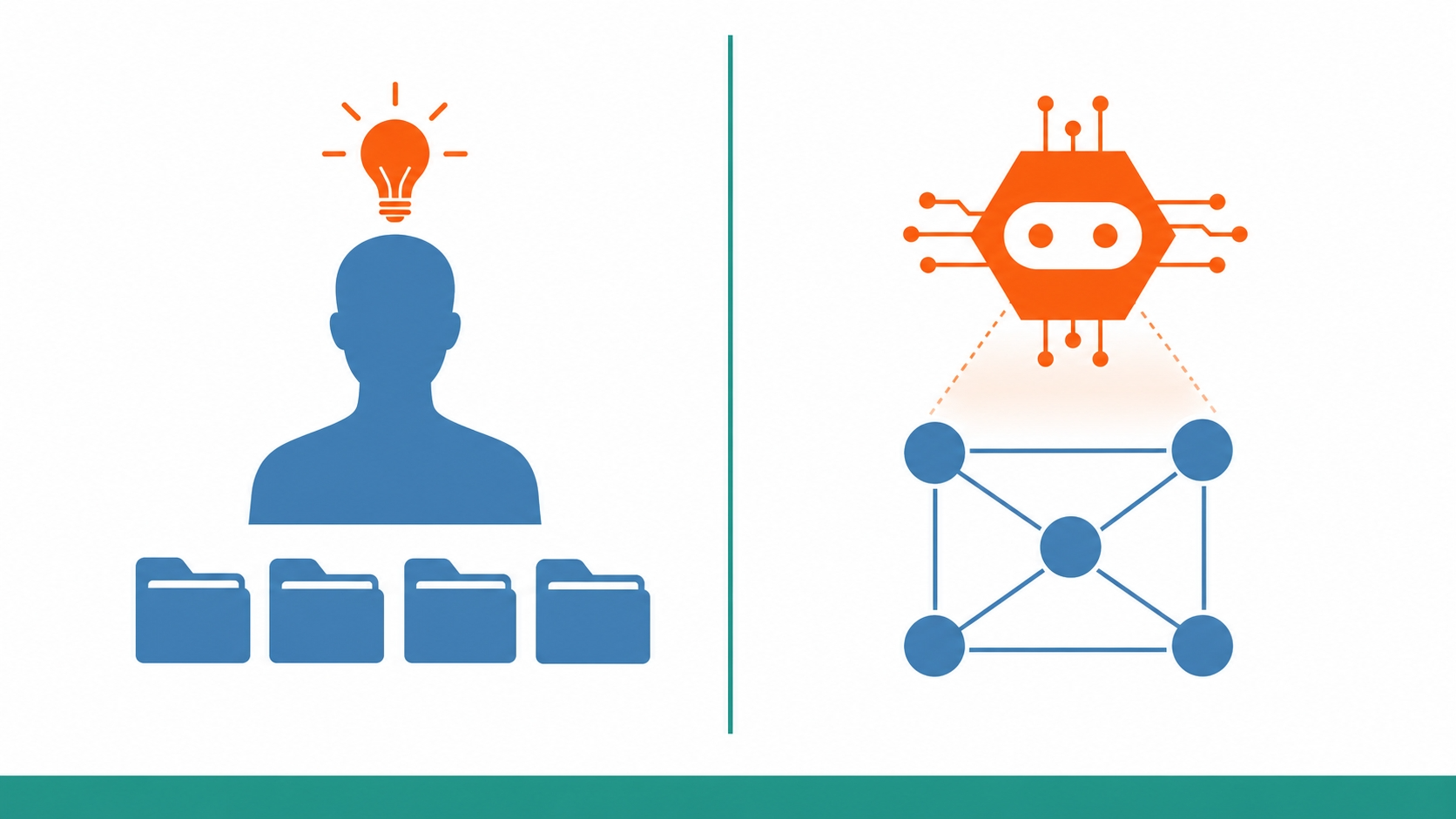
利用者が違うので、最終的に作るものは別物です。けれども「ぐちゃぐちゃのまま検索で頑張る」のではなく「先に構造化しておく」という発想は同じです。
社内の情報資産も、コードベースも、放っておくとどんどん肥大化して読めなくなる、というのは共通の悩みです。読める化を「人にとって」だけでなく「AI にとって」も施そう、という流れが、いま開発の世界で起きていると見ています。
終わりに
skill graph 系スキルは、まだ発展途上で、本番運用レベルの定着事例も多くは見えていません。ただ、発想としては「読める化を AI 側にも広げる」ものとして覚えておく価値があると思います。
フォルダ経営の延長で、コードや社内データの整理を考えるとき、こうした隣接領域の動きを観察しておくと、次に何が来るかが見えやすくなりそうです。

