
はじめに
「AIがデータを全部消してしまったら、会社はどうなる?」
ひとり法人・フリーランスにとって、この問いはゾッとするほどリアルです。
僕もちょっと前に、ClaudeCodeが、間違ってファイル消してしまってバックアップしても復元できなかったので、まじめにいまのAIの時代にどうやったら会社の資産を守れるのか、考えました。
大企業にはIT部門がいて、バックアップもDR(災害復旧)も仕組み化されています。
でも1人〜数人の会社では、だれかのハードディスクががそのまま「会社のサーバー」だったり、クラウドにとにかく管理しきれないデータがあります。
当社AppTalentHubは「Company as a Filesystem」をCredoに掲げ、事業計画からソースコード、顧客データまで、すべてをディレクトリ構造で管理することを徹底してます。
先日ふと「また勝手にAIがデータ消したら、全部復元できるのか?」と自問して、背筋が凍りました。
本記事では、実際にバックアップ体制を監査し、穴を埋め、復旧手順書まで整備した全過程を記録します。
監査してわかった「守れていないもの」
まず現状の棚卸しをしました。
守れているもの
- ソースコード → GitHubに複数リポジトリ
- ファイル全体 → NASに毎日ROBOCOPYでミラー
守れていなかったもの
- バージョン管理されていないプロジェクトが2つあった。 メインリポジトリの
.gitignoreで除外されているのに、独立した.gitも持っていない。GitHubにも履歴がない状態 - 機密データ(事業計画・顧客提案書)がPC+NASだけ。 同じ部屋にある2台が同時に壊れたら終わり
- NASにシークレット(APIキー等)が平文でコピーされていた。 バックアップスクリプトの除外設定が甘かった
- 「新しいPCで復元する手順」が誰の頭にも紙にもなかった
1つでも心当たりがあるなら、この先を読む価値があります。
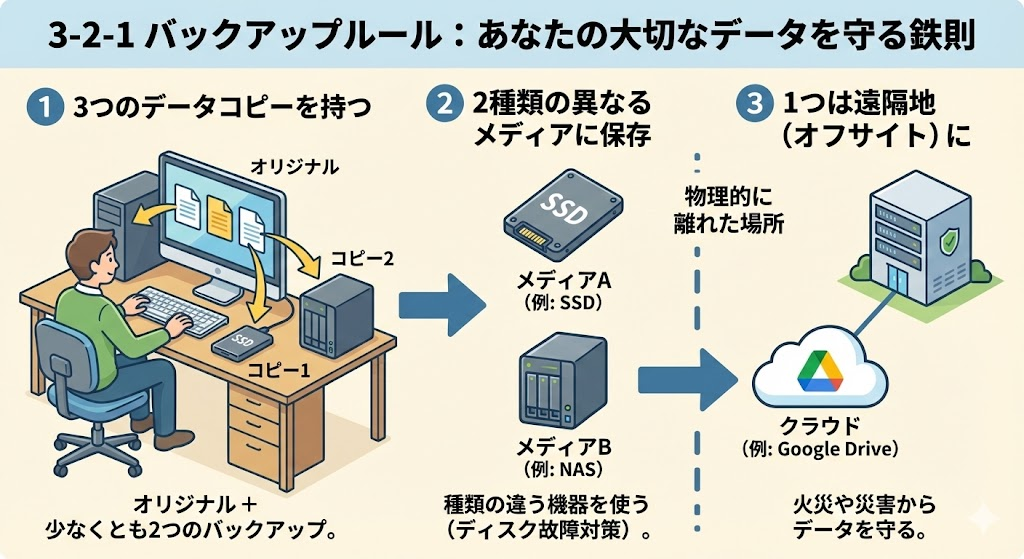
3-2-1ルールとは
バックアップの世界には「3-2-1ルール」という鉄則があります。
| ルール | 意味 |
|---|---|
| 3 コピー | データを最低3か所に保持する |
| 2 メディア | 異なる2種類の媒体を使う(SSD+NAS、SSD+クラウドなど) |
| 1 オフサイト | 最低1つは物理的に離れた場所に保管する |
自宅のPCとNASだけでは「2か所・1メディア・0オフサイト」。火事や盗難で両方失う可能性があります。クラウドを1つ加えるだけで、3-2-1が完成します。
実際にやった5つのこと
1. バージョン管理の空白を埋める
GitHubにpushされていなかった2プロジェクトにgit initし、プライベートリポジトリを作成してpushしました。
cd path/to/project
git init
git add -A
git commit -m "Initial commit"
gh repo create yourname/project --private --source=. --pushghはGitHub CLIです。1コマンドでリポジトリ作成からpushまで完結します。
ポイント:メインリポジトリの.gitignoreで除外しているディレクトリに、独立した.gitがあるか? これを全プロジェクトで確認しましょう。除外=「別で管理している」はずなのに、実は何も管理していない——これが最も危険なパターンです。
2. オフサイトバックアップ(Google ドライブ)
GitHubにpushできない機密データ(事業計画・顧客データ)は、クラウドストレージにバックアップします。当社はGoogle Workspaceを使っているため、Google ドライブを選びました。
Google Drive for Desktopをインストールすると、G:\マイドライブとしてローカルドライブにマウントされます。あとはROBOCOPYで定期ミラーするだけです。
set SOURCE=C:\Users\tsuba\AppTalentHub
set DEST=G:\マイドライブ\AppTalentHub-Confidential
robocopy "%SOURCE%\00_core\business_plan" "%DEST%\business_plan" /MIR
robocopy "%SOURCE%\04_sales_marketing\03_clients" "%DEST%\clients" /MIR/MIR(ミラー)オプションにより、ソース側で削除されたファイルはバックアップ側でも削除されます。Google ドライブ側にはゴミ箱があるため、誤削除してもWebから30日以内なら復元可能です。

3. NASバックアップからシークレットを除外
既存のbackup.batを監査したところ、.env(APIキー)やcredentials.json(OAuth認証)がそのままNASにコピーされていました。NASが盗まれたら全サービスのキーが漏洩します。
robocopy "%SOURCE%" "%DEST%" /MIR ^
/XD node_modules .next .git venv __pycache__ .expo ^
/XF .env .env.* credentials.json token.json *.exe除外すべきファイルのチェックリスト:
.env/.env.*— APIキー、データベース接続文字列credentials.json/token.json— OAuth認証情報*.exe/*.blockmap— ビルド成果物(再ビルドで復元可能)node_modules//venv/— 依存パッケージ(npm installで復元可能)
シークレットは「バックアップしない」が正解です。万一の喪失時は各サービスのコンソールから再発行します。
4. 復旧手順書を書く
バックアップがあっても、復元手順がわからなければ意味がありません。
当社は以下の3つのドキュメントを作成しました。
災害復旧手順書 — 新しいPCを買ってきてから、開発環境が動くまでの8ステップ。
ソフトウェアのインストール → Git設定 → リポジトリのclone → 機密データの復元 → プロジェクト別セットアップ → バックアップ再設定。
シークレット管理台帳 — どのプロジェクトにどんな.envがあり、再発行するにはどのURLに行けばいいかをまとめた一覧。実際のキー値は絶対に書きません。
| プロジェクト | シークレット | 再取得先 |
|---|---|---|
| project-a | ANTHROPIC_API_KEY | Anthropic Console |
| project-b | credentials.json | Google Cloud Console |
リポジトリ一覧 — ローカルパス、GitHub URL、公開/非公開の対応表。サブリポジトリが増えてくると「あれ、これどこにpushしてたっけ?」が起こります。一覧表があれば迷いません。
5. 同期チェックスクリプト
全リポジトリを巡回し、未commitの変更や未pushのコミットを一括チェックするバッチスクリプトを作りました。
[OK] AppTalentHub (main)
[OK] grant-pilot
[DIRTY] art_voice - 未コミット変更 3 件
[UNPUSH] MarkShot - 未push コミット 1 件バックアップは「取ったつもり」が一番怖い。定期的に実行して、漏れがないか確認します。
毎日定時に、メールでバックアップの連絡が来るようにしてます。

最終的なバックアップ体制
| データ | PC | NAS | クラウド(オフサイト) | 3-2-1 |
|---|---|---|---|---|
| ソースコード | ○ | ○ | GitHub | ○ |
| 機密データ | ○ | ○ | Google ドライブ | ○ |
| キャラクター画像 | ○ | ○ | Google ドライブ | ○ |
| シークレット | ○ | ×(除外) | 各サービスから再発行 | N/A |
アクションリスト
今日できることから始めましょう。
- 棚卸し(10分) — 自分のPCにある「失ったら終わるデータ」をリストアップする
- Git確認(5分) —
.gitignoreで除外しているディレクトリに、独立した.gitがあるか確認する - クラウド追加(30分) — Google ドライブやOneDriveをインストールし、機密フォルダのミラーを設定する
- 除外確認(5分) — NASバックアップから
.env等のシークレットが除外されているか確認する - 手順書(1時間) — 「新PCで復元する手順」をMarkdownで1枚書く
- テスト(随時) — 同期チェックスクリプトを月1で回す
全部で2時間。この2時間が、ある日突然の「全喪失」から会社を守ります。(僕はすでに1度やっちましたが。。)
まとめ
バックアップは「やっている」と「復元できる」の間に深い溝があります。
NASにコピーを取っていても、シークレットが混ざっていたり、Git履歴が欠けていたり、復元手順がなかったりすれば、いざという時に復元できません。
3-2-1ルールの本質は、単にコピーを増やすことではなく、「あらゆる障害シナリオで復元できる状態を維持すること」です。1人の会社だからこそ、仕組みで守る必要があります。

