

LLM(大規模言語モデル)を組み込んだアプリケーション開発において、誰もが直面する課題、それが「APIコスト」です。特に、Dify,n8nのようなプラットフォームで高度な情報抽出やエージェント機能を実装していると、テスト段階からトークン消費量が予想以上に膨らんでしまうケースは少なくありません。今回、私のアプリ開発の全体のAPIコストを約90%削減することができたので、そのやり方をメモしておきます。
正直、ここまでコスト削減インパクトがあるとはおもわず、いままでも、「あー、まぁ、なんかかかってるよね。」くらいのレベルだったので、気分で変えている程度なので、今後は、自分の戒めも込めて、ちゃんと書いておきます。
いま簡単な見直しで、30%~90%にまで削減できる可能性があるので、ぜひ見直してみてください。特に、モデルの費用や、新サービスは、目まぐるしく変わるので、ほんの数分で最新情報チェックしておくだけでも、開発には劇的なコスト削減が見込める可能性があります。
最初の課題:平均4万/回トークンを見直し
最適化前の私たちのアプリケーションは、PDFから特定のプロジェクト情報を抽出し、構造化データとして生成するタスクを担っていました。使用していたモデルは、高性能なGemini 2.5 Flashです。もちろんこのときも、モデルはいくつか試してましたが、初期のころは、トークンも5000-10000程度だったので、まぁかかっても1万円くらいかな程度でなめてました。
ところが、数か月にわたるプロンプトの改善から、確認してみると、
Difyのワークフローログを確認すると、1回の実行あたりに消費するトークン数は、平均して40,000〜50,000トークンに達していました。あれ?思ったよりも多くね?
このままでは、スケーラブルなサービス運用は困難です。(お金そんなにない。)
私たちは、2つの大きな改善に着手しました。
見直し1:モデルの見直し – FlashからFlash-Liteへの切り替え
最初のステップは、「タスクに最適なモデルは何か?」という問いから始まりました。正直最初は、モデル変わると出力が変わるのが怖くて、最初のFlashから変えてなかったのですが、さすがに40000トークンはでかい。
で、まずは、現在使っているモデルが適当なのか?を考えます。
数か月の傾向から、そもそも100万トークンサイズのものを裁かないことも分かったので、モデルの比較検討に
ChatGPT (GPT-4o)やClaude 3 Opusは、除外しました。今回の場合、とにかくモデル費用を抑えたかったので、以下のモデルが対象です。
【費用対効果モデル】比較 2025/8/10 時点参考 *詳細は、各公式ページみてください。
情報抽出、分類など、コストを重視する大規模な処理向け
| モデル | 入力価格 (Input) | 出力価格 (Output) |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 |
| ChatGPT (GPT-3.5 Turbo) | (参考) ~$0.50 | (参考) ~$1.50 |
| Claude 3 Haiku | (参考) ~$0.25 | (参考) ~$1.25 |
いまのところGeminiが一番安そうということなので、Geminiをチョイスします。
Gemini 2.5 Flashは非常に高性能ですが、私たちの「構造化された情報抽出」タスクには、より軽量で費用対効果の高いGemini 2.5 Flash-Liteでも十分な精度が出せるのではないか、と仮説を立てました。
公式の料金表を見てみましょう。(100万トークンあたり)
| モデル | 入力価格 (Input) | 出力価格 (Output) |
| Gemini 2.5 Flash | $0.30 | $2.50 |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 |
Flash-LiteはFlashに比べて入力で1/3、出力では約1/6という、圧倒的なコスト優位性があります。このモデル変更だけでも、コストを約77%削減できる計算になり、大きな一歩となりました。思った以上に変わります。
車の運転に例えると分かりやすいです。
- Flash: 様々な道(複雑なタスク)をそつなくこなせる、バランスの取れたスポーティーなセダン。
- Flash-Lite: 舗装された決まった道(明確なタスク)を、誰よりも速く低燃費で走ることに特化した軽量なシティコミューター。
精度比較の早見表
| 比較項目 | Gemini 2.5 Flash | Gemini 2.5 Flash-Lite |
| 得意なこと | 性能とコストのバランス | 速度とコスト効率 |
| 推論・思考能力 | 高い | 限定的 |
| 明確な指示の実行精度 | 非常に高い | 非常に高い(Flashと同等) |
| 応答速度 | 高速 | 最速 |
| コスト | 低い | 最安 |
見直し2:プロンプト改善 – 「指示の質」でトークンを削る
次に、AIへの「指示書」であるプロンプトそのものにメスを入れました。
この改善により、1回の実行に必要なトークン数は平均4万から、約1万8千まで半減させることに成功しました。
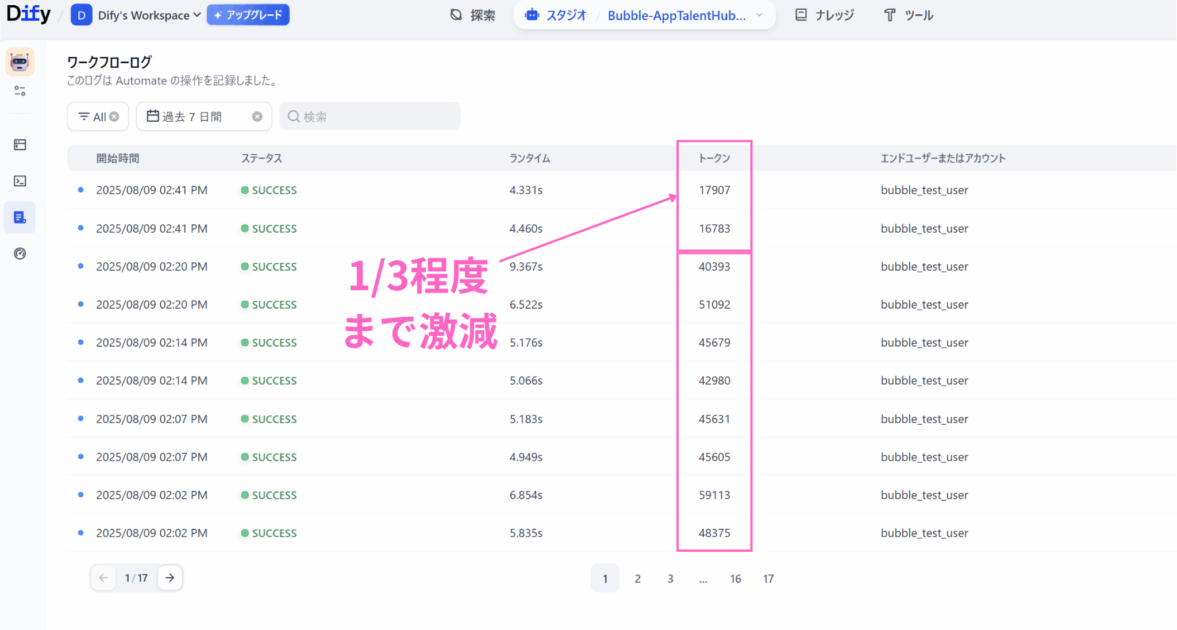
なぜ、トークンは半分になったのか?
1. 「人間向けの丁寧さ」から「機械向けの明確さ」への転換
【Before】 「あなたは、情報を抽出する専門のAIアシスタントです。あなたのタスクは…」
【After】 「入力テキストから全てのプロジェクト情報を抽出し、JSON配列形式で出力してください。」
【理由】 APIとして利用する場合、AIは「タスクを実行するプログラム」です。丁寧な前置きは多くの場合トークンの無駄遣いになります。改善後のプロンプトは、実行すべきタスクを単刀直入に命令しています。
2. 「繰り返しの指示」から「共通ルールの定義」への転換
【Before】 ・「抽出タグ_スキル」について:社内ナレッジベースを参照し、カンマ区切りで出力。 ・「抽出タグ_役割」について:社内ナレッジベースを参照し、カンマ区切りで出力。
【After】 # ナレッジベース参照ルール 以下のキーは、社内ナレッジベースを参照し、カンマ区切りで出力する。 - 抽出タグ_スキル - 抽出タグ_役割
【理由】 これがトークン削減で一番効きました、これだけで1万トークンくらい違います。
共通処理をルールとして一度だけ定義することで、入力トークンを大幅に削減し、メンテナンス性も向上させました。
(この辺、理屈はプログラムと同じなんですけど、文章だとそういう処理をしているのかって理解がわからなかった。)
3. 「文章による説明」から「構造による伝達」への転換
【Before】 ルールが長い文章で記述されている。
【After】 # 指示 - 項目A: ルールA - 項目B: ルールB
【理由】 Markdownの見出しやリストでプロンプトを構造化すると、AIは情報の階層や関係性を即座に理解でき、指示漏れや解釈ミスが起こる確率が格段に下がります。
【ケーススタディ】実際のプロンプト構造 Before/After
上記3つの改善原則がどのように適用されたか、今回使用したプロンプトの構造と量の変化を、完全に匿名化した形でご紹介します。
【BEFORE】改善前のプロンプト構造
(人間が読むことを意識し、丁寧だが冗長な指示)
あなたは、提供された文書から、情報を抽出・要約する専門のAIアシスタントです。あなたのタスクは、文書に含まれる複数の項目を個別に識別し、項目ごとに指定された8つの要素を正確に抽出し、JSON配列形式で出力することです。
### 全体的な処理フロー
1. 項目の境界を特定します。
2. 各項目の情報を抽出します。
3. JSON配列の生成します。
### ナレッジベースの参照について
- `抽出タグ_A` の出力は、ナレッジベースのドキュメント `カテゴリA` を参照してください。
- `抽出タグ_B` の出力は、ナレッジベースのドキュメント `カテゴリB` を参照してください。
- `抽出タグ_C` の出力は、ナレッジベースのドキュメント `カテゴリC` を参照してください。
### 抽出・要約ルール
* **抽出項目_1**: 項目の名称を特定します。必須項目です。
* **抽出項目_2**: 項目の開始時期を`YYYY-MM-DD`形式で抽出します。
* **抽出項目_3**: 項目の終了時期を`YYYY-MM-DD`形式で抽出します。
* ...(など、各項目に対する自然言語での詳細な説明が続く)
* **抽出タグ_A**: 文書から関連情報を抽出し、ナレッジベース `カテゴリA` を参照し、対応する公式な名称に変換後、すべてをカンマ(`,`)区切りの単一の文字列としてください。
* **抽出タグ_B**: 文書から関連情報を抽出し、ナレッジベース `カテゴリB` を参照し、対応する公式な名称に変換後、カンマ(`,`)区切りの単一の文字列としてください。
* **抽出タグ_C**: 文書から関連情報を抽出し、ナレッジベース `カテゴリC` を参照し、対応する公式な名称に変換後、カンマ(`,`)区切りの単一の文字列としてください。
### 出力フォーマット
出力は、JSON配列でなければなりません。説明文やマークダウン記号を一切含めず、純粋なJSON配列のみを生成してください。
【AFTER】改善後のプロンプト構造
(AIが処理することを前提とし、簡潔で構造化された指示)
# 指示
入力テキストから全ての情報を抽出し、JSON配列形式で出力せよ。配列の各要素は、後述の8つのキーを持つ1項目分のJSONオブジェクトとする。
# 識別ルール
- 項目は「項目名:」などの明確な見出しで識別する。
- 1つのグループ下に複数の項目が記載されている場合も、それぞれを独立した項目として扱う。
# JSONオブジェクトの各キーのルール
- "抽出項目_1": 項目の名称を抽出(必須)
- "抽出項目_2": 開始時期を`YYYY-MM-DD`で抽出(日が不明な場合は`01`)
- "抽出項目_3": 終了時期を`YYYY-MM-DD`で抽出(日が不明な場合は月の末日、不明時は `""`)
- "抽出項目_4": 関連組織名を抽出(必須)
- "抽出項目_5": 概要と成果を150字程度で要約。
- "抽出タグ_A", "抽出タグ_B", "抽出タグ_C": 下記の共通ルールを適用。
# 共通ルール:ナレッジベース参照
以下のキーの値は、ナレッジベース内の対応するドキュメントを参照し、最も適切な公式な名称に変換後、カンマ(`,`)区切りの単一文字列とせよ。該当がない場合は空文字 `""` とする。
- "抽出タグ_A": ドキュメント `カテゴリA` を参照。
- "抽出タグ_B": ドキュメント `カテゴリB` を参照。
- "抽出タグ_C": ドキュメント `カテゴリC` を参照。
# 全体的な出力ルール
- 必須項目が抽出不能な場合、値は "抽出不可" とする。
- 出力は純粋なJSON配列のみとし、説明文やマークダウンは一切含めないこと。
驚くべき成果:APIコストを約90%削減
「モデル変更」と「プロンプト改善」を組み合わせた最終的なコスト削減効果を見てみましょう。(入力:出力=8:2と仮定)
- 【Before】最適化前のコスト: 40,000トークン on
Gemini 2.5 Flash→ 合計:$0.0296 - 【After】最適化後のコスト: 約18,000トークン on
Gemini 2.5 Flash-Lite→ 合計:$0.00288
1実行あたりのコストは約90%削減され、当初の「1/3になれば」という期待を遥かに上回る成果を達成しました。
【コストシミュレーション】10,000回の実行で約4万円の差
この1回あたりのコスト差が、実際の運用でどれほどのインパクトを持つか、シミュレーションしてみましょう。仮に、この抽出処理を1ヶ月に10,000回実行したと仮定します。(※$1=155円で計算)
- 最適化前の月間コスト:
$0.0296 × 10,000回 =$296(約45,880円) - 最適化後の月間コスト:
$0.00288 × 10,000回 =$28.8(約4,464円)
その差は月間で約$267(約41,416円)にもなります。年間では約50万円近い差です。 たった1回の実行ではセント単位のわずかな差ですが、処理回数が増えるにつれて、モデル選択とプロンプト改善がいかに重要なコスト削減策であるかが明確にわかります。
なぜ出力トークンは変わらなかったのか?
高性能なFlashから軽量なFlash-Liteにモデルを変更しても、抽出される情報の精度はほとんど変わりませんでした。
これは、プロンプトが非常に明確で、AIの「裁量」の余地をなくし、タスクを具体的に制御するほうに修正できたことや、もともとのモデルがそこまで高度ではなかったと思います。
プロンプトの質を高めてAIのタスクを単純化できたからこそ、より安価なモデルへの切り替えが成功し、コスト削減効果を最大化できたのです。
【発展編】さらに上目指す上級テクニック
今回の改善では実施しませんでしたが、プロンプトエンジニアリングの改善手法です。
1. キャッシュ戦略:同じ質問に二度答えない同じ入力に対して、毎回AIに答えを生成させるのは最大の無駄です。
一度得られた結果を保存(キャッシュ)し、再利用する仕組みを導入します。
- Geminiのコンテキストキャッシュを活用する
例えば、非常に長いPDF資料(数万〜数十万トークン)について、複数回に分けて質問をしたい場合に使います。 最初に一度だけPDFを「コンテキストキャッシュ」としてAPIに記憶させておけば、2回目以降の質問では、毎回長いPDFを送信する必要がなくなり、質問部分の短いトークンだけで済みます。長文読解タスクでは絶大な効果を発揮します。
今回は、PDF数ページなので、使いませんでした。 - アプリケーションレベルでのキャッシュ
例えば、Bubbleのようなアプリのデータベースに、一度実行したプロンプトと、それに対するAIの回答をセットで保存しておく方法です。次にユーザーが全く同じリクエストをした際には、AIを呼び出すのではなく、データベースから保存した結果を返すようにします。よくある質問への回答や、頻繁に参照される情報の要約などに有効です。
これもいま、アプリ側のデータベースをできるだけシンプルにしようと思ったので、無し。
2. モデルカスケード戦略:適材適所でAIを使い分ける
すべてのタスクを最初から高性能なモデルに任せるのではなく、
まず最も安価なモデルに挑戦させ、失敗した場合のみ、より高性能なモデルにエスカレーションさせます。
これは、次回試してみたいやり方。
【具体的な処理フロー】
- まず、APIリクエストを最も安価な
Gemini 2.5 Flash-Liteに送ります。 - 返ってきた答えをプログラムで検証します。
- 期待通りのJSON形式か?
- 「分かりません」「情報が不足しています」といった回答ではないか?
- もし答えが不十分だった場合(例えば全体の5%の難しいケース)、同じプロンプトを、今度は高性能な
Gemini 1.5 Proに自動で再送信します。
この仕組みにより、簡単な95%のタスクは最安の料金でこなし、本当に難しい5%のタスクにのみ高いコストを払うという、極めて効率的なコスト配分が実現できます。
まとめ
LLMアプリケーションのコスト最適化は、「適切なモデルの選択」と「質の高いプロンプトエンジニアリング」という両輪で進めることで、最大の効果を発揮します。
今回の実例が、あなたのプロジェクトのコスト課題を解決する一助となれば幸いです。また次、会いましょうー。

